Q. what is YARN ?
Ans .
1 . ResourceManager :
The ResourceManager typically runs on its own machine and is responsible for scheduling and allocating resources. The two main components of the ResourceManager are:
if you are familiar with Hadoop 1.x, note that YARN splits up the functionality of the JobTracker into two separate processes:
The ResourceManager allocates resources for applications but does not manage the lifecycle of applications. Instead, applications are managed by an ApplicationMaster that runs on a node in the cluster. Each application running in the cluster requires its own ApplicationMaster.
The NodeManager is a daemon process that runs on each DataNode in the cluster. Its responsibilities include:
3. ApplicationMaster :
The per-application ApplicationMaster is the bootstrap process that initiates a YARN application once it gets past the application submission and its own launch.
The responsibilities of the AM include:

Ans .
Ans .
YARN consists of the following main components:
- ResourceManager
- NodeManager
- ApplicationsMaster
The ResourceManager typically runs on its own machine and is responsible for scheduling and allocating resources. The two main components of the ResourceManager are:
- Scheduler
- Applications Manager (AsM)
if you are familiar with Hadoop 1.x, note that YARN splits up the functionality of the JobTracker into two separate processes:
The ResourceManager allocates resources for applications but does not manage the lifecycle of applications. Instead, applications are managed by an ApplicationMaster that runs on a node in the cluster. Each application running in the cluster requires its own ApplicationMaster.
2. NodeManager :
- Communicating its status with the RM
- Tracking the health of the node
- Overseeing the lifecycle management of containers
- Monitoring resource usage of each container (i.e. memory and CPUs)
- Managing resource localization (for JAR files, libraries, and any other application-specific files used by containers)
- Managing the logs generated by containers
3. ApplicationMaster :
The per-application ApplicationMaster is the bootstrap process that initiates a YARN application once it gets past the application submission and its own launch.
The responsibilities of the AM include:
- Negotiating appropriate containers from the ResourceManager
- Working with the NodeManagers to execute and monitor the containers and their resource consumption
- Providing fault tolerance.
The benefits of the AM include:
- Extensibility Hadoop computing can now be more than Java MapReduce applications
- Scalability Hadoop clusters can now be considerably larger, because the ResourceManager does not manage fault tolerance (a problem with the old JobTracker that caused bottlenecks and limited the size of a Hadoop cluster)
- YARN applications have been executed on clusters of over 10,000 nodes.
YARN LIFE CYCLE :

Q. What is YARN container ? How does it work ?
Ans .
Containers :
A container in YARN represents a unit of work in an application. A container has the following behaviors:
- Runs on a node, managed by a NodeManager
- Makes use of some resources on the node, specifically: memory and CPU currently allocated to a container
- Depends on some libraries that are represented as local resources, which are provided by the NodeManager using a LocalResource
- Performs needed work
- The container does the actual work of the specific YARN application. This is where custom code appears that allows you to do whatever it is you need to do to your big data on Hadoop.
Q. What is difference between MR1 and MR2 (YARN) ?
Ans .
MRv1 uses the JobTracker to create and assign tasks to task trackers, which can become a resource bottleneck when the cluster scales out far enough (usually around 4,000 clusters).
MRv2 (aka YARN, "Yet Another Resource Negotiator") has a Resource Manager for each cluster, and each data node runs a Node Manager. In MapReduce MRv2, the functions of the JobTracker have been split between three services.
The ResourceManager is a persistent YARN service that receives and runs applications (a MapReduce job is an application) on the cluster. It contains the scheduler, which, as previously, is pluggable.
The MapReduce-specific capabilities of the JobTracker have been moved into the MapReduce Application Master, one of which is started to manage each MapReduce job and terminated when the job completes.
The JobTracker function of serving information about completed jobs has been moved to the JobHistory Server.
The TaskTracker has been replaced with the NodeManager, a YARN service that manages resources and deployment on a host. It is responsible for launching containers, each of which can house a map or reduce task.
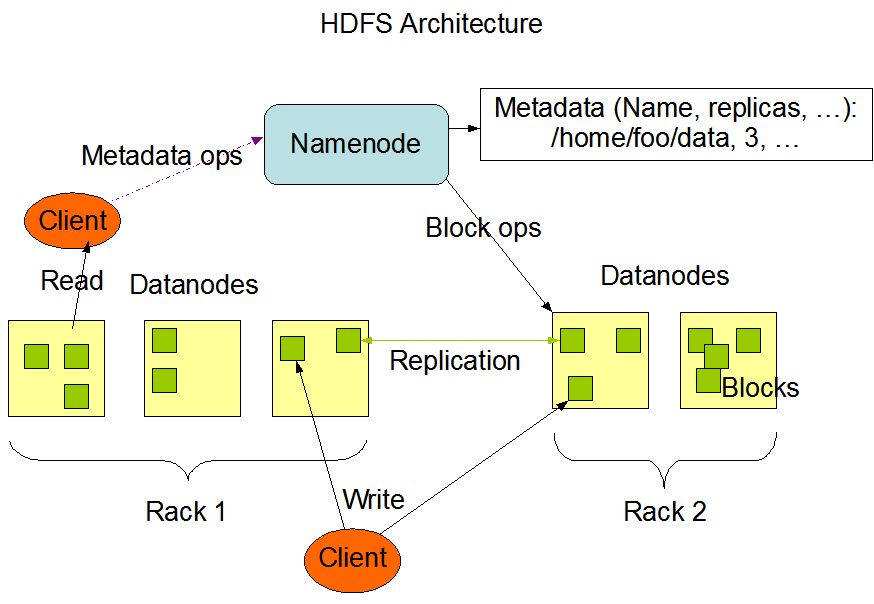
Q. How does Read/write happens in HDFS ?
Ans .